Introduction
Model compression is usually described as a teacher-student problem. We first train or select a large teacher model, then train a smaller student model to imitate its predictions, intermediate features, or representation geometry. This strategy is useful, but it has a stubborn limitation: the student is usually a different, smaller network, so it may not have enough capacity to carry what the teacher knows.
The paper Beyond Student: An Asymmetric Network for Neural Network Inheritance studies this limitation from a different angle. Instead of asking only “how can a small student imitate a large teacher?”, it asks:
Can a compressed model directly inherit the teacher’s parameters and structure?
This shift is important. If the compressed model is initialized from the teacher’s own weights, then compression is not only behavioral imitation. It becomes a form of neural network inheritance: keep the most informative directions in the teacher, restructure them into a smaller network, and then fine-tune from a much better starting point.
Paper links:
- Paper HTML: ar5iv:2602.09509
- arXiv abstract: arXiv:2602.09509
- arXiv DOI: 10.48550/arXiv.2602.09509
According to arXiv, the paper was submitted on February 10, 2026 and revised on February 11, 2026. The authors are Yiyun Zhou, Jingwei Shi, Mingjing Xu, Zhonghua Jiang, and Jingyuan Chen.
Background: Why Compression Is Hard
A large neural network has two kinds of useful information:
- Function-level knowledge: what outputs it gives, how it ranks classes, and how it embeds samples.
- Parameter-level structure: how its layers organize features, channels, and transformations.
Knowledge distillation mainly transfers the first part. A common distillation objective is:
where $\mathbf{z}_t$ and $\mathbf{z}_s$ are teacher and student logits, $T$ is the temperature, and $\alpha$ balances the task loss and the distillation loss.
This is useful, but it does not remove the capacity gap. If the student is too small or architecturally different, the teacher can provide a better target, but the student may still be unable to represent the same function well.
InherNet is motivated by this problem. Its view is:
- If the teacher already contains a good representation, do not throw its weights away.
- If the teacher is too large, compress the weights through low-rank structure.
- If a single low-rank branch is too narrow, add several lightweight expansion heads and use a gate to combine them.
Related Work Context
It helps to separate InherNet from several nearby ideas.
Knowledge distillation transfers output behavior or features from teacher to student. It is flexible because the student can have a different architecture, but it may suffer when the student cannot express the teacher’s function.
Pruning and quantization reduce model size by removing weights or reducing numeric precision. These approaches can be very effective for deployment, but they usually work after or during training and may require careful hardware-aware tuning.
Low-rank decomposition factorizes a large matrix or convolution kernel into smaller pieces. This is close to InherNet, but classical low-rank compression often replaces one layer with a narrow chain of layers and can disturb the original architecture.
LoRA-style adaptation learns low-rank updates to a frozen base model:
InherNet is different. It is not mainly learning a small update on top of the teacher. It decomposes the teacher’s own weight matrix and uses that decomposition as the inherited model’s initialization and structure.
Main Idea
InherNet combines two forms of inheritance.
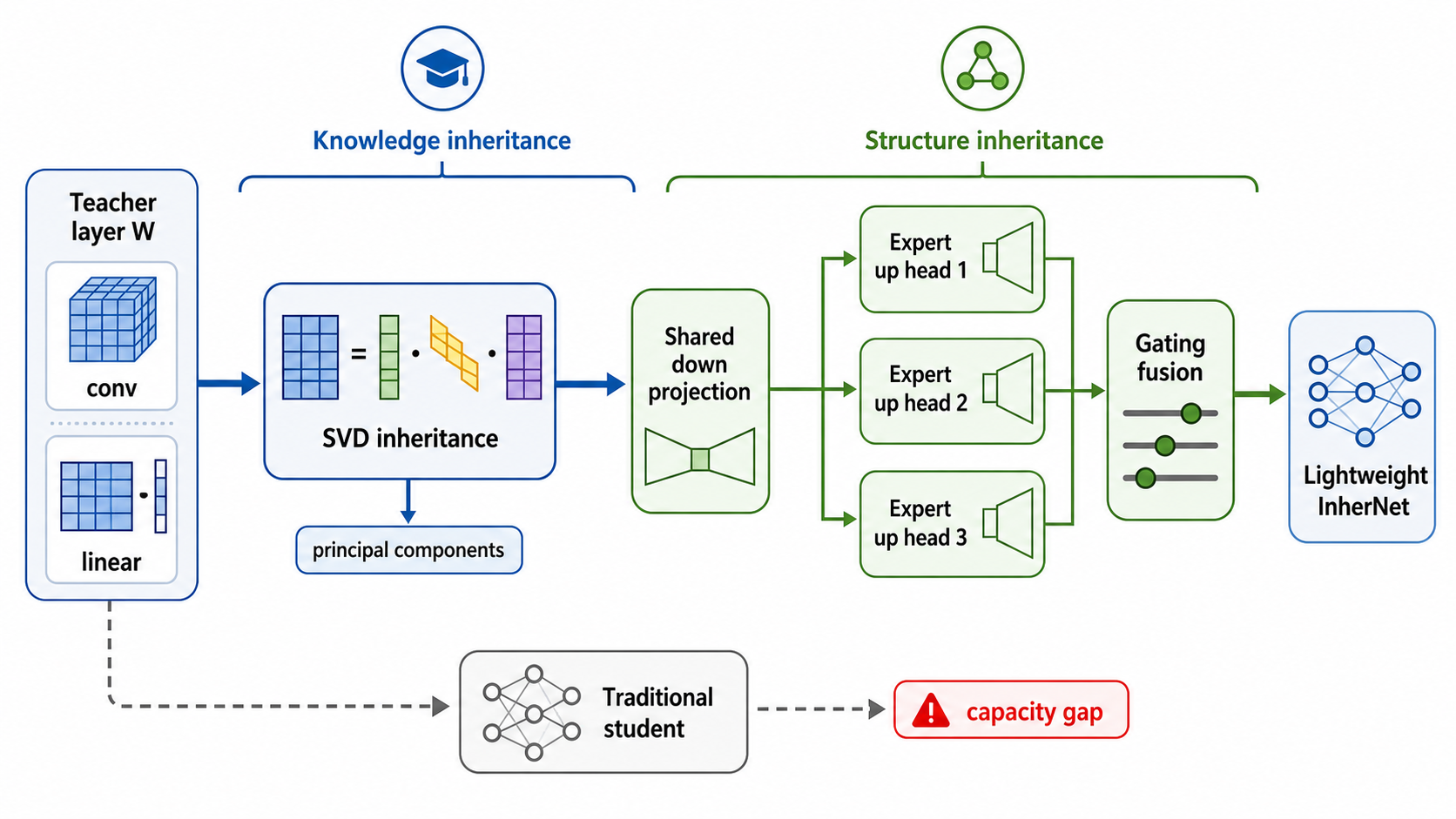
The left side of the diagram is knowledge inheritance. The teacher layer weight is decomposed by SVD, and the dominant components are used to initialize a lower-rank representation.
The right side is structure inheritance. A shared down projection compresses the feature dimension, several expert up heads expand it back, and a gating module fuses the heads. This creates an asymmetric structure: one shared bottleneck, multiple reconstruction paths.
That asymmetry is the main architectural choice. A single low-rank branch may be too restrictive. Multiple heads give the compressed layer more expressive routes while still sharing the expensive reduction part.
SVD as Knowledge Inheritance
For a linear layer with teacher weight
the singular value decomposition is:
The rank-$r$ approximation keeps the top singular values and their singular vectors:
This matters because SVD gives the best rank-$r$ approximation under the usual Frobenius-norm objective:
In practical terms, the largest singular directions are treated as the teacher’s most important linear transformations. Instead of initializing a student randomly and hoping distillation recovers them, InherNet starts from these inherited directions.
The decomposed layer can be read as:
For convolution layers, the same idea can be applied after reshaping the convolution kernel into a matrix. After decomposition, the factors are reshaped back into convolution-compatible weights. This is why the paper describes the method as architecture-agnostic for both linear and convolutional layers.
Structure Inheritance: One Down, Many Ups
If InherNet only used a single low-rank factorization, the compressed layer might become too narrow. The paper therefore builds an asymmetric inherited layer:
then multiple expert heads reconstruct candidate outputs:
A gating module combines them:
The parameter-count intuition is simple. A dense layer has:
The inherited asymmetric layer has roughly:
Compression is useful when:
So the rank $r$ controls how much spectral knowledge is preserved, while the number of heads $M$ controls how much reconstruction diversity the compressed layer has.
Why the Asymmetry Helps
The one-down-many-ups structure is not just a cosmetic design.
The shared down projection forces all heads to rely on a common compressed representation. This keeps the inherited model parameter-efficient. The multiple up heads then let the model recover different output patterns from that same bottleneck.
This is similar in spirit to a lightweight mixture-of-experts layer, but the goal is not to build a huge sparse model. The goal is to give a compressed inherited model enough local flexibility to avoid the worst failure mode of low-rank compression: losing too much expressive diversity.
The gate is also important. Without gating, the heads would be combined too rigidly. With gating, different inputs can emphasize different inherited reconstruction paths.
Convergence Intuition
SVD initialization gives the inherited network a better starting point than random initialization. It places the model close to a low-rank approximation of the teacher, so early training does not need to rediscover the teacher’s dominant directions from scratch.
This also explains why InherNet can converge faster in experiments. The optimization problem is still non-convex, but the initialization is more informative. The training process starts from:
instead of starting from a randomly initialized student:
That does not mean SVD alone solves compression. Low-rank approximation can still discard important directions, especially if the teacher’s spectrum decays slowly. The practical contribution is the combination: SVD initialization preserves the dominant directions, while the asymmetric heads and gate restore some lost flexibility.
Experimental Takeaways
The paper evaluates InherNet on unimodal and multimodal tasks, including image classification, language understanding, and vision-language evaluation.
A few results are worth highlighting.
First, on CIFAR-100 teacher-student settings, InherNet variants are often stronger than the listed student baselines of similar size. For example, in one ResNet56-to-ResNet20 setting, the student is reported at 69.06, the teacher at 72.34, and InherNet Large at 73.67. This is a useful sign: inheritance can sometimes recover or even exceed the teacher’s reported accuracy after compression and fine-tuning.
Second, the multimodal experiments use CC3M for visual-language pretraining and ImageNet validation for zero-shot classification. The reported InherNet model improves several retrieval and classification metrics compared with the listed ResNet-101 teacher and CLIP-KD-style student baselines. This suggests that the method is not limited to a single CNN compression toy setting.
Third, the ablation studies support the design:
- removing SVD initialization hurts strongly, which supports the knowledge-inheritance claim;
- removing the gate weakens adaptive routing;
- replacing the asymmetric structure with a more symmetric variant performs worse, which supports the one-down-many-ups design;
- increasing rank is usually more important than blindly adding heads, because rank directly controls how much teacher information is kept.
The important practical lesson is that InherNet is not only “low rank plus fine-tuning.” Its performance comes from the interaction between rank, asymmetric structure, gate, and inherited initialization.
Limitations and Open Questions
The method is promising, but several questions remain.
First, rank selection is critical. If $r$ is too small, important teacher directions are lost. If $r$ is too large, compression becomes weak. A deployment-ready version needs a reliable way to choose rank under memory, latency, and accuracy constraints.
Second, the gating and multiple heads add overhead. Parameter count may decrease, but real latency depends on kernel efficiency, hardware, batch size, and whether the decomposed layers are friendly to the inference backend.
Third, teacher weights are not always strongly low-rank. SVD works best when the singular spectrum decays enough that the top components carry most of the information. Some layers may compress well, while others may need higher rank or a different compression strategy.
Fourth, inheritance is complementary to other compression tools. In practice, InherNet may need to be compared or combined with pruning, quantization, sparsity, and hardware-aware distillation.
Finally, there is a deeper question about what “knowledge” means inside a neural network. SVD captures parameter-space energy, but parameter-space importance and function-space importance are not always identical. The strong empirical results suggest that SVD is a useful proxy, but it is still a proxy.
Conclusion
InherNet is best understood as a move from student imitation to network inheritance. Instead of building a small model from scratch and asking it to mimic a teacher, it decomposes the teacher’s own weights, keeps the dominant directions through SVD, and rebuilds them into a lightweight asymmetric network.
The core mechanism is simple enough to remember:
- Decompose teacher weights with SVD.
- Keep a low-rank shared down projection.
- Add several expert up heads for expressive reconstruction.
- Use gating fusion to combine the heads.
- Fine-tune from this inherited initialization.
For readers interested in model compression, the main takeaway is that architecture and initialization should be considered together. A compressed model is not only a smaller container for distilled behavior. It can also be a structured descendant of the original network.

