Preface by the author
最近在复习 ML 的时候又翻到了很久以前读过的一篇 CNN 入门文章。这类文章的好处是不会一上来就把人扔进大量公式里,而是先用图像、filter、feature map 这些直观概念把问题讲清楚。所以这篇笔记还是沿用原来那种比较散的学习笔记风格:先从我个人理解的角度解释 CNN 是什么,再补上一些必要的公式和 DL 里的训练逻辑。
我之前在 CUHK 选过 Prof. Hongsheng Li 的 _ML for SP Applications_,那门课对我后来的 research thesis 也很有帮助。不过我的背景更偏 IoT 和 embedded systems,数学功底不算特别扎实,所以这篇文章的目标不是写成教科书,而是把 CNN 里最容易卡住新人的地方尽量讲顺。
Disclaimer
这篇文章主要是个人学习总结,行文风格会比较松散。为了保证可读性,我不会把每个推导都写到最严格的形式,但会尽量保证核心概念不出错。如果你发现理解有偏差,欢迎通过 GitHub issue 交流。
Abstract
Convolutional Neural Network 听起来像一个很重的术语,但它的核心思想其实很朴素:图像里的有用信息通常不是孤立的单个像素,而是局部区域里反复出现的结构,比如边缘、角点、纹理、部件,最后再组合成物体类别。
CNN 的思想确实受到视觉神经科学的启发,例如 Hubel 和 Wiesel 关于感受野的研究;工程上可以追溯到 Fukushima 的 Neocognitron、LeCun 等人的 LeNet。真正让 CNN 在大众视野里爆发的是 AlexNet 在 2012 年 ImageNet 比赛中的表现。之后,VGG、Inception、ResNet 等结构不断改进网络深度、连接方式、非线性层和训练策略,使 CNN 成为深度学习中最经典的一类模型。
如果只想抓住 CNN 的主线,可以先记住三件事:
- CNN 把图像看成张量,而不是一张“图片文件”。
- 卷积层通过可学习的 filters 在局部窗口里抽取 feature maps。
- 多层卷积会把低级视觉特征逐步组合成高级语义表示,最后交给分类头输出预测结果。
1. From Image to Tensor
人类看图像的时候会直接说“这是一只猫”或者“这是一辆车”,但模型看到的是数字矩阵。对于一张 RGB 图片,假设分辨率是 $H \times W$,那么它通常会被表示成:
其中 $C=3$ 对应 red、green、blue 三个通道。如果一次训练送入 $B$ 张图片,那么输入 batch 可以写成:
当然,不同框架对 channel 的位置有不同习惯。例如 TensorFlow 常见的是 NHWC,PyTorch 常见的是 NCHW。但本质上都是在说:图像是一组有空间结构的多通道数值。
这也是 CNN 和普通 fully connected network 的关键差别。假如直接把 $256 \times 256 \times 3$ 的图像 flatten 成一个长向量,模型会丢掉很多空间邻近关系;而 CNN 会保留“附近像素更可能共同构成局部结构”这个 inductive bias。
2. What Makes CNN Work
我觉得理解 CNN 时,最重要的是先抓住三个词:locality, parameter sharing, translation equivariance。
Locality 指的是卷积层只看局部窗口。比如一个 $3 \times 3$ filter 每次只处理当前位置附近的小区域。图像里的边缘、纹理、角点往往就是局部结构,所以这很自然。
Parameter sharing 指的是同一个 filter 会在整张图上滑动。也就是说,如果某个 filter 学会检测“竖直边缘”,它不需要在左上角、右下角分别学习一套参数。这样既减少了参数量,也让模型更容易泛化。
Translation equivariance 的意思是:如果输入里的某个局部模式移动了位置,feature map 里对应的响应也会跟着移动。CNN 不会因为一个边缘从左边移动到右边就完全认不出来。
用一句话概括,CNN 的核心假设是:视觉特征具有局部性,并且同一种局部模式可以出现在图像的不同位置。
3. Convolution Layer
经过预处理的 data 传入 CNN 时,最先遇到的通常是 convolutional layer。卷积层不是一个固定的图像处理算子,而是包含一组可学习的 filters/kernels。这些 kernel 的数值会在训练中通过反向传播学出来,而不是由人手工指定。
如果输入是 $\mathbf{x}$,某个卷积核是 $\mathbf{W}$,输出 feature map 是 $\mathbf{y}$,那么一个简化的二维卷积可以写成:
这里 $k$ 表示第 $k$ 个 filter,也就是第 $k$ 个输出通道;$F_h$ 和 $F_w$ 是 kernel 的高度和宽度;$b_k$ 是 bias。
如果先忽略 dilation,卷积输出的空间尺寸大致由 kernel size、padding 和 stride 决定:
其中 $P$ 是 padding,$S$ 是 stride。Padding 可以让边缘像素也被充分利用,也可以控制输出尺寸;stride 越大,下采样越明显。
在下面这个例子里,input 是一个 $5 \times 5$ 的二维矩阵,我们使用一个 $3 \times 3$ filter 在上面滑动。每次滑动时,窗口内的数值和 filter 对应元素相乘再求和,得到 feature map 中的一个值。
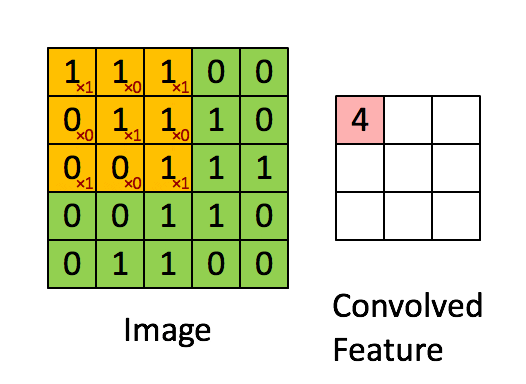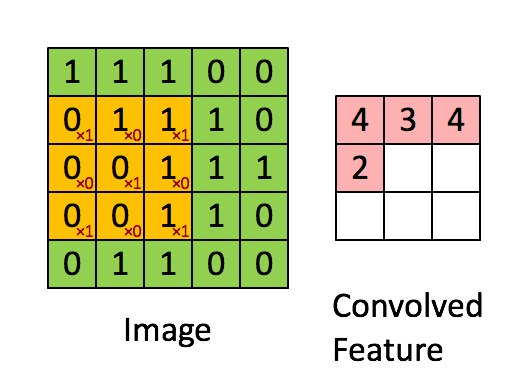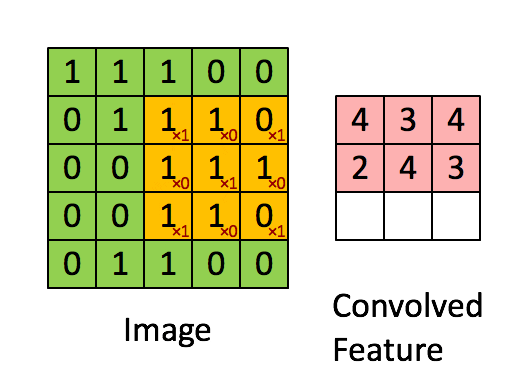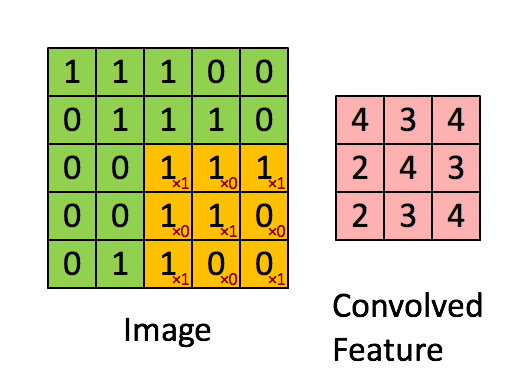
我一开始理解 CNN 时,只是把卷积层看成线性代数里的矩阵运算。这个角度没有错,但还不够直观。更直观的理解是:一个 filter 就像一个小型 pattern detector。如果某个局部图像块和这个 filter 想检测的 pattern 很像,输出就大;如果不像,输出就小。
比如下面这个简化示例中,一个 $7 \times 7$ filter 可以被看成一条曲线。当它扫过一张图时,越像这条曲线的局部区域,响应越强。
![]()
这就是 feature extraction 的基本逻辑。早期层的 filters 可能学到边缘、颜色对比和简单纹理;更深层的 filters 会在前面 feature maps 的基础上检测更复杂的形状、部件甚至语义模式。
4. Nonlinearity: Why ReLU Is Needed
如果 CNN 只有卷积层,那么每一层本质上仍然是线性变换。很多线性层堆在一起,最后仍然等价于一个线性变换,表达能力会很有限。所以在卷积之后,我们通常会接一个 nonlinear activation。
最常见的是 ReLU:
它的作用很直接:小于 0 的响应被压成 0,大于 0 的响应保留。直观上,这像是在说“这个 feature 是否被激活”。ReLU 计算便宜,也能缓解 sigmoid/tanh 在深层网络中容易出现的梯度消失问题。
所以一个常见的局部结构是:
当然,现代 CNN 还会加入 BatchNorm、Dropout、Residual connection 等结构,但对入门理解来说,上面这条链已经足够重要。
5. Pooling and Downsampling
Pooling layer 的作用通常是降低 feature map 的空间尺寸,让模型对小范围位移更不敏感,同时减少后续计算量。最常见的是 max pooling 和 average pooling。
Max pooling 可以写成:
其中 $\Omega_{i,j}$ 是 pooling window 覆盖的局部区域。它保留局部区域里最强的响应,比较像“只要这个 feature 在附近出现过,就把它记下来”。
Average pooling 则是求平均,更像是在做局部平滑:
在很多现代网络里,最后也会用 global average pooling,把每个 channel 的整张 feature map 平均成一个数,从而避免巨大的 flatten 向量。
6. Receptive Field
CNN 里还有一个很重要但容易被忽略的概念:receptive field。它指的是某一层某个神经元在原始输入图像中能“看到”的区域。
第一层的 $3 \times 3$ conv 只能看到 $3 \times 3$ 的像素块;第二层的一个神经元虽然仍然可能是 $3 \times 3$ conv,但它看到的是第一层 feature map 上的 $3 \times 3$ 区域,而第一层每个点又对应原图的一小片区域。所以网络越深,后面的神经元通常拥有越大的 effective receptive field。
这也解释了为什么 CNN 能从 low-level feature 逐步走向 high-level feature:
- 浅层:边缘、角点、颜色对比。
- 中层:纹理、简单形状、局部部件。
- 深层:物体部件、语义组合、类别相关特征。
7. Fully Connected Layer and Softmax
卷积层和 pooling 层主要负责 feature extraction。到网络末尾,我们需要把这些 feature 映射成具体任务的输出。对于图像分类任务,这通常意味着输出一个长度为 $K$ 的 logits 向量:
Softmax 会把 logits 转换成概率分布:
如果标签是 one-hot vector $\mathbf{y}$,分类任务常用 cross-entropy loss:
如果真实类别是 $t$,那么上式就变成:
也就是说,模型给正确类别的概率越高,loss 越小。训练时,反向传播会根据 loss 对所有参数求梯度,包括卷积核、bias、BatchNorm 参数和 classifier head 中的权重。
举个例子,假设 CIFAR-10 有 10 个类别,softmax 输出为:
这表示模型认为第 4 个类别的概率最高。注意这里的“第 4 个类别”不是某一个神经元机械地检测“dog face”或者“wheel”,而是前面很多 distributed features 共同作用后的分类结果。
8. How CNN Learns
从训练角度看,CNN 做的事情可以概括为:
- Forward pass:输入图像经过 conv、activation、pooling、classifier,得到预测概率。
- Loss calculation:用 cross-entropy 等 loss 衡量预测和真实标签的差距。
- Backpropagation:计算 loss 对每个参数的梯度。
- Optimizer step:用 SGD、Adam 等优化器更新参数。
如果用最简单的 SGD 表示,参数更新可以写成:
其中 $\eta$ 是 learning rate。对 CNN 来说,$\theta$ 包括所有可学习的 kernel weights、biases 和后续分类层参数。
所以 CNN 不是“人为设计好一堆边缘检测器”,而是在数据和 loss 的驱动下自己学出合适的 filters。人类提供的是结构上的先验:局部连接、权重共享、层级组合。
9. A Tiny CNN Pipeline
为了把上面的内容串起来,可以想象一个最简单的 image classifier:
- Input image
- Conv(3x3, 32 filters)
- ReLU
- MaxPool(2x2)
- Conv(3x3, 64 filters)
- ReLU
- MaxPool(2x2)
- Global Average Pooling
- Linear layer
- Softmax
- Class probabilities
这个结构虽然很小,但已经包含了 CNN 的主要思想:
- Conv 负责提取局部模式。
- ReLU 提供非线性表达能力。
- Pooling 降低空间尺寸并扩大后续感受野。
- Global average pooling 或 flatten 把空间 feature 变成向量。
- Linear + softmax 输出每个类别的概率。
10. Common Misunderstandings
误解 1:Convolution layer 一定会压缩图像。
不一定。是否压缩取决于 stride、padding、kernel size 和是否接 pooling。使用 same padding 且 stride = 1 时,输出空间尺寸可以和输入一样。
误解 2:Filter 越多,feature map 一定越小。
Filter 数量决定输出 channel 数,不直接决定 height 和 width。空间尺寸主要由 stride、padding、pooling 等控制。
误解 3:Fully connected layer 是 CNN 最重要的部分。
对于图像任务来说,真正体现 CNN 特点的是前面的卷积特征提取。分类头很重要,但它主要负责把 learned representation 映射到 label space。
误解 4:CNN 已经过时。
Transformer 在视觉任务中非常强,但 CNN 的归纳偏置仍然有价值。很多工业场景、嵌入式视觉任务、轻量模型和 hybrid architecture 里,CNN 仍然是非常实用的选择。
Conclusion
CNN 的强大之处,不是因为它神秘,而是因为它把图像任务中的几个合理假设变成了可训练结构:局部区域有意义,同一类 pattern 可以出现在不同位置,低级特征可以逐步组合成高级语义。
从公式上看,卷积层只是局部加权求和;从系统角度看,CNN 是一种把 image tensor 转换成 semantic representation 的层级特征学习机器。理解这一点后,再去看 LeNet、AlexNet、VGG、ResNet 或轻量 CNN,就会更容易抓住它们到底是在改进什么。

